






发布于:2021-01-01
你真的理解 K8s 中的 requests 和 limits 吗?





在 K8s 集群中部署资源的时候,你是否经常遇到以下情形:
- 经常在 K8s 集群种部署负载的时候不设置 CPU
requests或将 CPUrequests设置得过低(这样“看上去”就可以在每个节点上容纳更多 Pod )。在业务比较繁忙的时候,节点的 CPU 全负荷运行。业务延迟明显增加,有时甚至机器会莫名其妙地进入 CPU 软死锁等“假死”状态。 - 类似地,部署负载的时候,不设置内存
requests或者内存requests设置得过低,这时会发现有些 Pod 会不断地失败重启。而不断重启的这些 Pod 通常跑的是 Java 业务应用。但是这些 Java 应用本地调试运行地时候明明都是正常的。 - 在 K8s 集群中,集群负载并不是完全均匀地在节点间分配的,通常内存不均匀分配的情况较为突出,集群中某些节点的内存使用率明显高于其他节点。 K8s 作为一个众所周知的云原生分布式容器编排系统,一个所谓的事实上标准,其调度器不是应该保证资源的均匀分配吗?
如果在业务高峰时间遇到上述问题,并且机器已经 hang 住甚至无法远程 ssh 登陆,那么通常留给集群管理员的只剩下重启集群这一个选项。如果你遇到过上面类似的情形,想了解如何规避相关问题或者你是 K8s 运维开发人员,想对这类问题的本质一探究竟,那么请耐心阅读下面的章节。我们会先对这类问题做一个定性分析,并给出避免此类问题的最佳实践,最后如果你对 K8s requests 和 limits 的底层机制感兴趣,我们可以从源码角度做进一步地分析,做到“知其然也知其所以然”。
问题分析
首先我们需要知道对于 CPU 和内存这 2 类资源,他们是有一定区别的。 CPU 属于可压缩资源,其中 CPU 资源的分配和管理是 Linux 内核借助于完全公平调度算法( CFS )和 Cgroup 机制共同完成的。简单地讲,如果 pod 中服务使用 CPU 超过设置的 CPU limits, pod 的 CPU 资源会被限流( throttled )。对于没有设置limit的 pod ,一旦节点的空闲 CPU 资源耗尽,之前分配的 CPU 资源会逐渐减少。不管是上面的哪种情况,最终的结果都是 Pod 已经越来越无法承载外部更多的请求,表现为应用延时增加,响应变慢。这种情形对于上面的情形 1 。内存属于不可压缩资源, Pod 之间是无法共享的,完全独占的,这也就意味着资源一旦耗尽或者不足,分配新的资源一定是会失败的。有的 Pod 内部进程在初始化启动时会提前开辟出一段内存空间。比如 JVM 虚拟机在启动的时候会申请一段内存空间。如果内存 requests 指定的数值小于 JVM 虚拟机向系统申请的内存,导致内存申请失败( oom-kill ),从而 Pod 出现不断地失败重启。这种情形对应于上面的情形 2 。对于情形 3 ,实际上在创建 pod 的过程中,一方面, K8s 需要拨备包含 CPU 和内存在内的多种资源,这里的资源均衡是包含 CPU 和内存在内的所有资源的综合考量。另一方面, K8s 内置的调度算法不仅仅涉及到“最小资源分配节点”,还会把其他诸如 Pod 亲和性等因素考虑在内。并且 k8s 调度基于的是资源的 requests 数值,而之所以往往观察到的是内存分布不够均衡,是因为对于应用来说,相比于其他资源,内存一般是更紧缺的一类资源。另一方面, K8s 的调度机制是基于当前的状态。比如当出现新的 Pod 进行调度时,调度程序会根据其当时对 Kubernetes 集群的资源描述做出最佳调度决定。但是 Kubernetes 集群是非常动态的,由于整个集群范围内的变化,比如一个节点为了维护,我们先执行了驱逐操作,这个节点上的所有 Pod 会被驱逐到其他节点去,但是当我们维护完成后,之前的 Pod 并不会自动回到该节点上来,因为 Pod 一旦被绑定了节点是不会触发重新调度的。
最佳实践
由上面的分析我们可以看到,集群的稳定性直接决定了其上运行的业务应用的稳定性。而临时性的资源短缺往往是导致集群不稳定的主要因素。集群一旦不稳定,轻则业务应用的性能下降,重则出现相关结点不可用。那么如何提高集群的稳定性呢?一方面,可以通过编辑 Kubelet 配置文件来预留一部分系统资源,从而保证当可用计算资源较少时 kubelet 所在节点的稳定性。 这在处理如内存和硬盘之类的不可压缩资源时尤为重要。另一方面,通过合理地设置 pod 的 QoS 可以进一步提高集群稳定性:不同 QoS 的 Pod 具有不同的 OOM 分数,当出现资源不足时,集群会优先 Kill 掉 Best-Effort 类型的 Pod ,其次是 Burstable 类型的 Pod ,最后是Guaranteed 类型的 Pod 。因此,如果资源充足,可将 QoS pods 类型均设置为 Guaranteed 。用计算资源换业务性能和稳定性,减少排查问题时间和成本。同时如果想更好的提高资源利用率,业务服务也可以设置为 Guaranteed ,而其他服务根据重要程度可分别设置为 Burstable 或 Best-Effort 。下面我们会以 Kubesphere 平台为例,演示如何方便优雅地配置 Pod 相关的资源。
KubeSphere 资源配置实践
前面我们已经了解到 K8s 中requests、limits这 2 个参数的合理设置对整个集群的稳定性至关重要。而作为 K8s 的发行版 Kubephere ,极大地降低了 K8s 的学习门槛,配合简介美观的 UI 界面,你会发现有效运维原来是一件如此轻松的事情。下面我们将演示如何在 KubeSphere 平台中配置容器的相关资源配额与限制。
相关概念
在进行演示之前,让我们再回顾一下K8s相关概念。
requests 与 limits 简介
为了实现 K8s 集群中资源的有效调度和充分利用, K8s 采用requests和limits两种限制类型来对资源进行容器粒度的分配。每一个容器都可以独立地设定相应的requests和limits。这 2 个参数是通过每个容器 containerSpec 的 resources 字段进行设置的。一般来说,在调度的时候requests比较重要,在运行时limits比较重要。
resources:
requests:
cpu: 50m
memory: 50Mi
limits:
cpu: 100m
memory: 100Mi
requests定义了对应容器需要的最小资源量。这句话的含义是,举例来讲,比如对于一个 Spring Boot 业务容器,这里的requests必须是容器镜像中 JVM 虚拟机需要占用的最少资源。如果这里把 pod 的内存requests指定为 10Mi ,显然是不合理的,JVM 实际占用的内存 Xms 超出了 K8s 分配给 pod 的内存,导致 pod 内存溢出,从而 K8s 不断重启 pod 。
limits定义了这个容器最大可以消耗的资源上限,防止过量消耗资源导致资源短缺甚至宕机。特别的,设置为 0 表示对使用的资源不做限制。值得一提的是,当设置limits而没有设置requests时,Kubernetes 默认令requests等于limits。
进一步可以把requests和limits描述的资源分为 2 类:可压缩资源(例如 CPU )和不可压缩资源(例如内存)。合理地设置limits参数对于不可压缩资源来讲尤为重要。
前面我们已经知道requests参数会最终的 K8s 调度结果起到直接的显而易见的影响。借助于 Linux 内核 Cgroup 机制,limits参数实际上是被 K8s 用来约束分配给进程的资源。对于内存参数而言,实际上就是告诉 Linux 内核什么时候相关容器进程可以为了清理空间而被杀死( oom-kill )。
总结一下:
- 对于 CPU,如果 pod 中服务使用 CPU 超过设置的
limits,pod 不会被 kill 掉但会被限制。如果没有设置 limits ,pod 可以使用全部空闲的 CPU 资源。 - 对于内存,当一个 pod 使用内存超过了设置的
limits,pod 中 container 的进程会被 kernel 因 OOM kill 掉。当 container 因为 OOM 被 kill 掉时,系统倾向于在其原所在的机器上重启该 container 或本机或其他重新创建一个 pod。 - 0 <= requests <=Node Allocatable, requests <= limits <= Infinity
Pod 的服务质量( QoS )
Kubernetes 创建 Pod 时就给它指定了下列一种 QoS 类:Guaranteed,Burstable,BestEffort。
- Guaranteed:Pod 中的每个容器,包含初始化容器,必须指定内存和CPU的
requests和limits,并且两者要相等。 - Burstable:Pod 不符合 Guaranteed QoS 类的标准;Pod 中至少一个容器具有内存或 CPU
requests。 - BestEffort:Pod 中的容器必须没有设置内存和 CPU
requests或limits。
结合结点上 Kubelet 的CPU管理策略,可以对指定 pod 进行绑核操作,参见官方文档。
准备工作
您需要创建一个企业空间、一个项目和一个帐户 ( ws-admin ),务必邀请该帐户到项目中并赋予 admin 角色。有关更多信息,请参见创建企业空间、项目、帐户和角色。
设置项目配额( Resource Quotas )
- 进入项目基本信息界面,依次直接点击“项目管理 -> 编辑配额”进入项目的配额设置页面。
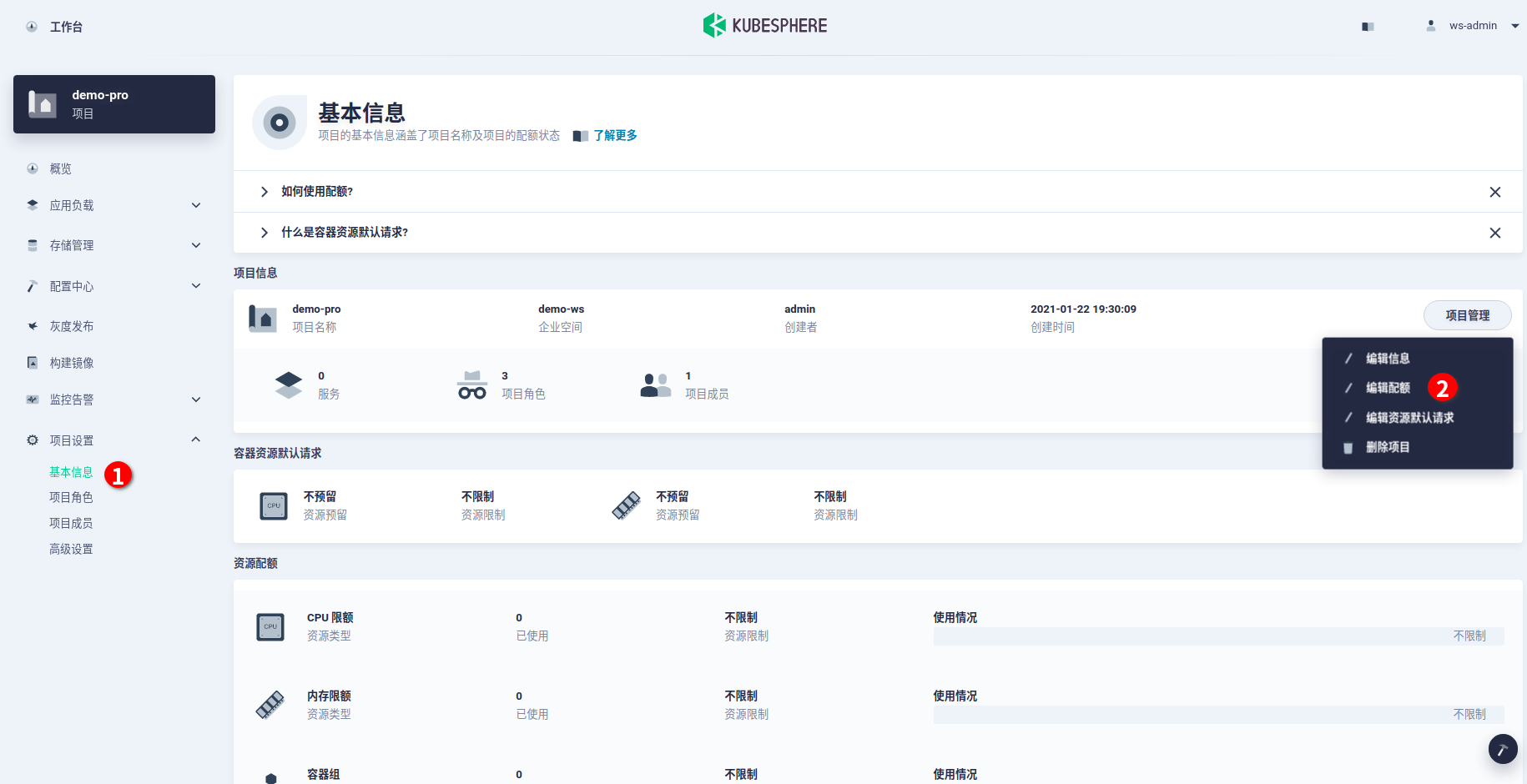
- 进入项目配额页面,为该项目分别指定
requests和limits配额。
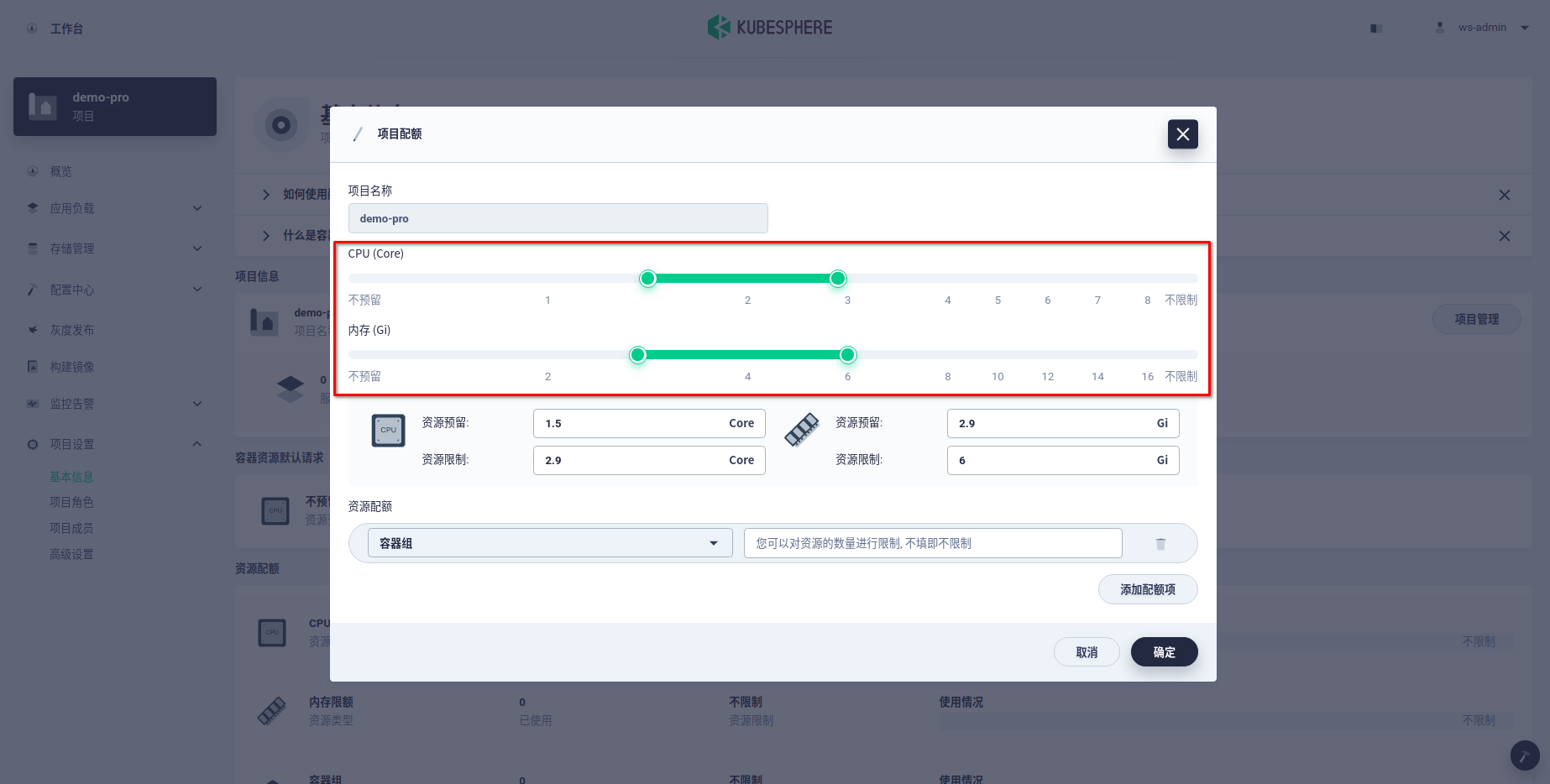
设置项目配额的有 2 方面的作用:
- 限定了该项目下所有 pod 指定的
requests和limits之和分别要小于等与这里指定的项目的总requests和limits。 - 如果在项目中创建任何一个容器没有指定
requests或者limits,那么相应的资源会创建报错,并会以事件的形式给出报错提示。
可以看到,设定项目配额以后,在该项目中创建任何容器都需要指定requests和limits,隐含实现了所谓的“code is law”,即人人都需要遵守的规则。
Kubesphere中的项目配额等价于 K8s 中的 resource quotas ,项目配额除了能够以项目为单位管理 CPU 和内存的使用使用分配情况,还能够管理其他类型的资源数目等,详细信息参见资源配额。
设置容器资源的默认请求
上面我们已经讨论过项目中开启了配额以后,那么之后创建的 pod 必须明确指定相应的 requests 和 limits 。事实上,在实际的测试或者生产环境当中,大部分 pod 的 requests 和 limits 是高度相近甚至完全相同的。有没有办法在项目中,事先设定好默认的缺省 requests 和 limits ,当用户没有指定容器的 requests 和 limits 时,直接应用默认值,若 pod 已经指定 requests 和 limits 是否直接跳过呢?答案是肯定的。
- 进入项目基本信息界面,依次直接点击“项目管理 -> 编辑资源默认请求”进入项目的默认请求设置页面。
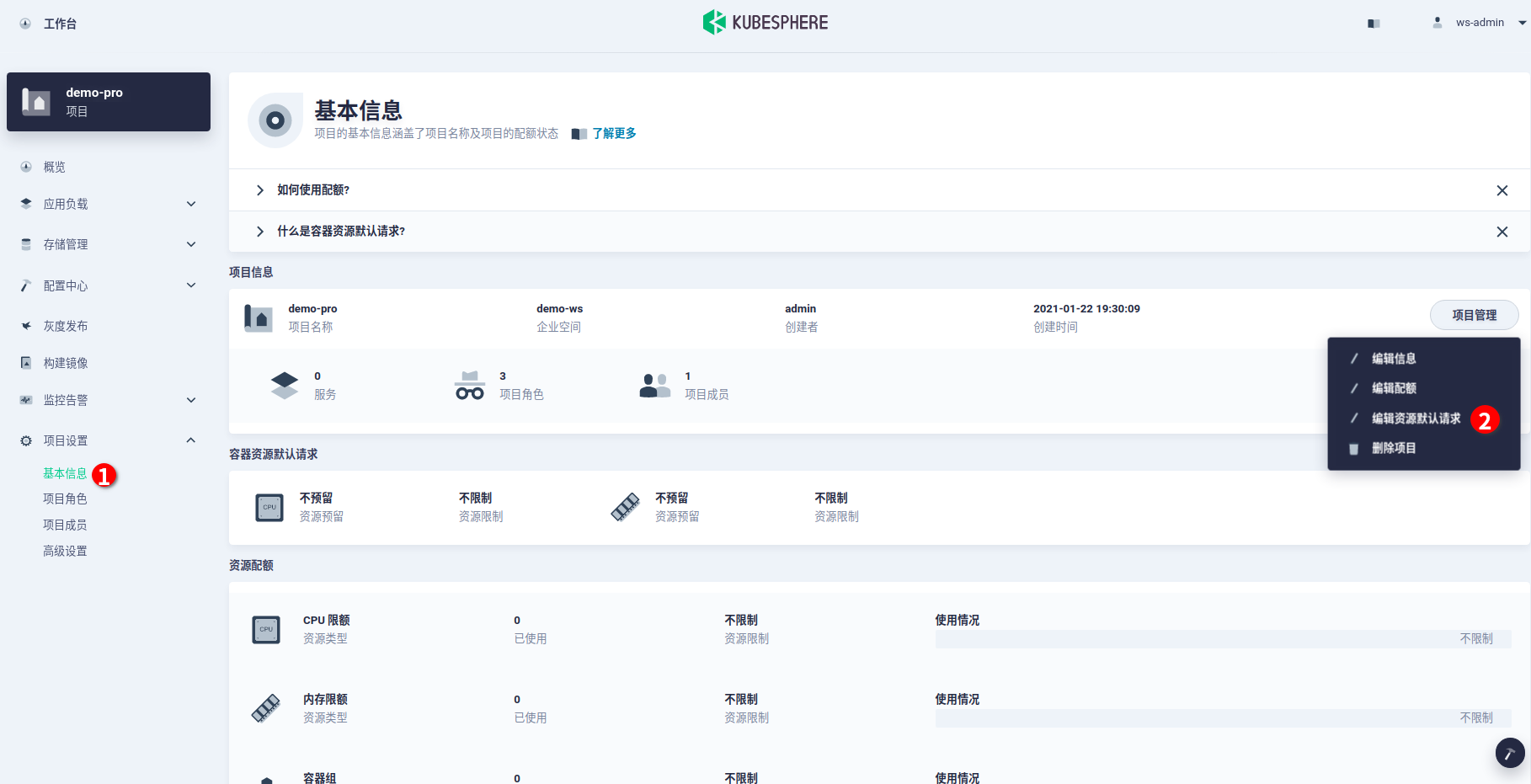
- 进入项目配额页面,为该项目分别指定 CPU 和内存的默认值。
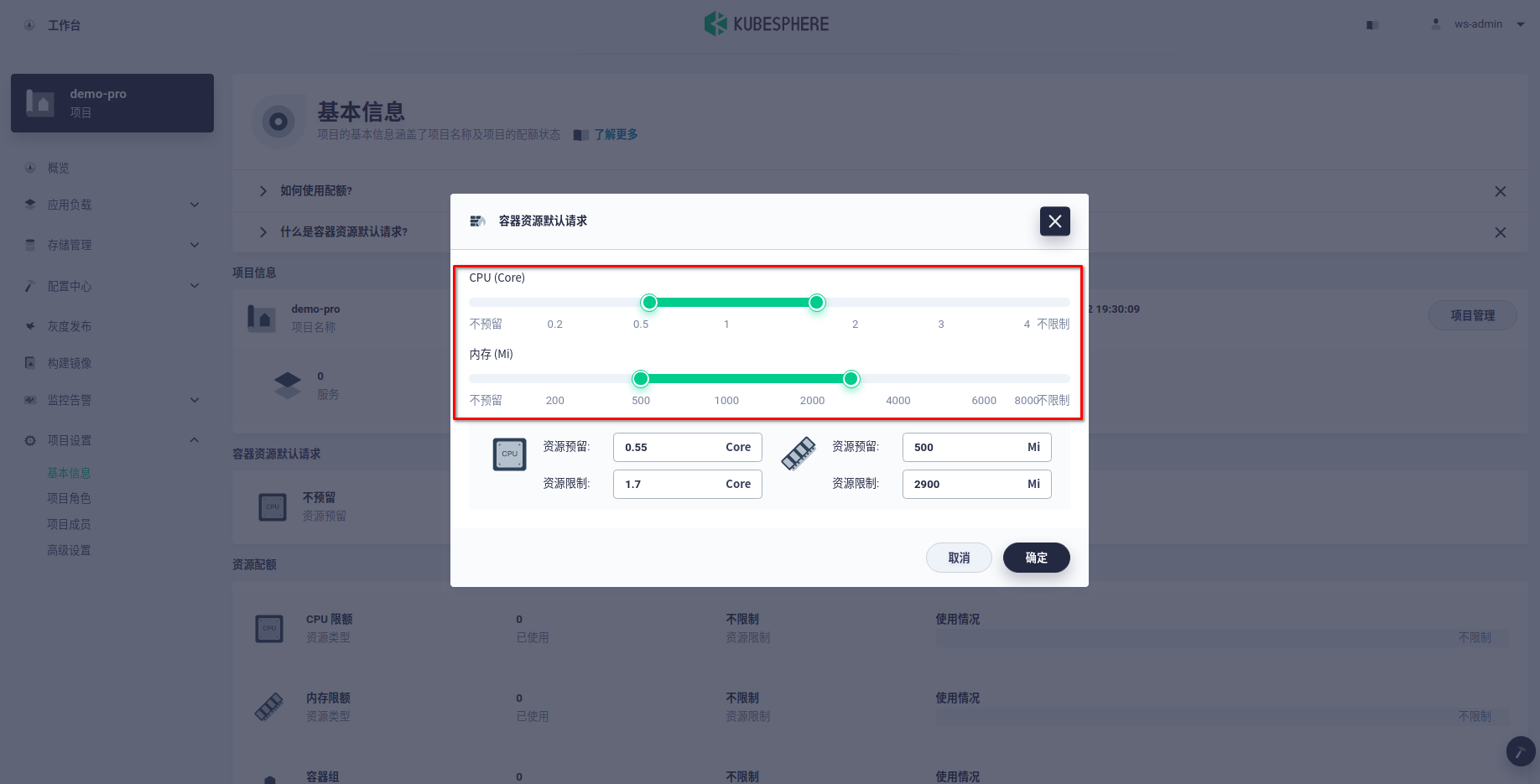
KubeSphere 中的项目种的容器资源默认请求是借助于 K8s 中的 Limit Ranges ,目前 KubeSphere 支持 CPU 和内存的
requests和limits的默认值设定。
前面我们已经了解到,对于一些关键的业务容器,通常其流量和负载相比于其他 pod 都是比较高的,对于这类容器的requests和limits需要具体问题具体分析。分析的维度是多个方面的,例如该业务容器是 CPU 密集型的,还是 IO 密集型的。是单点的还是高可用的,这个服务的上游和下游是谁等等。另一方面,在生产环境中这类业务容器的负载从一个比较长的时间维度看的话,往往是具有周期性的。因此,业务容器的历史监控数据可以在参数设置方面提供重要的参考价值。而 KubeSphere 在最初的设计中,就已经在架构层面考虑到了这点,将 Prometheus 组件无缝集成到 KubeSphere 平台中,并提供纵向上至集群层级,下至 pod 层级的完整的监控体系。横向涵盖 CPU ,内存,网络,存储等。一般,requests值可以设定为历史数据的均指,而limits要大于历史数据的均指,最终数值还需要结合具体情况做一些小的调整。
源码分析
前面我们从日常 K8s 运维出发,描述了由于 requests 和 limits参数配置不当而引起的一系列问题,阐述了问题产生的原因并给出的最佳实践。下面我们将深入到 K8s 内部,从代码里表征的逻辑关系来进一步分析和验证上面给出的结论。
requests 是如何影响 K8s 调度决策的?
我们知道在 K8s 中 pod 是最小的调度单位,pod 的requests与 pod 内容器的requests关系如下:
func computePodResourceRequest(pod *v1.Pod) *preFilterState {
result := &preFilterState{}
for _, container := range pod.Spec.Containers {
result.Add(container.Resources.Requests)
}
// take max_resource(sum_pod, any_init_container)
for _, container := range pod.Spec.InitContainers {
result.SetMaxResource(container.Resources.Requests)
}
// If Overhead is being utilized, add to the total requests for the pod
if pod.Spec.Overhead != nil && utilfeature.DefaultFeatureGate.Enabled(features.PodOverhead) {
result.Add(pod.Spec.Overhead)
}
return result
}
...
func (f *Fit) PreFilter(ctx context.Context, cycleState *framework.CycleState, pod *v1.Pod) *framework.Status {
cycleState.Write(preFilterStateKey, computePodResourceRequest(pod))
return nil
}
...
func getPreFilterState(cycleState *framework.CycleState) (*preFilterState, error) {
c, err := cycleState.Read(preFilterStateKey)
if err != nil {
// preFilterState doesn't exist, likely PreFilter wasn't invoked.
return nil, fmt.Errorf("error reading %q from cycleState: %v", preFilterStateKey, err)
}
s, ok := c.(*preFilterState)
if !ok {
return nil, fmt.Errorf("%+v convert to NodeResourcesFit.preFilterState error", c)
}
return s, nil
}
...
func (f *Fit) Filter(ctx context.Context, cycleState *framework.CycleState, pod *v1.Pod, nodeInfo *framework.NodeInfo) *framework.Status {
s, err := getPreFilterState(cycleState)
if err != nil {
return framework.NewStatus(framework.Error, err.Error())
}
insufficientResources := fitsRequest(s, nodeInfo, f.ignoredResources, f.ignoredResourceGroups)
if len(insufficientResources) != 0 {
// We will keep all failure reasons.
failureReasons := make([]string, 0, len(insufficientResources))
for _, r := range insufficientResources {
failureReasons = append(failureReasons, r.Reason)
}
return framework.NewStatus(framework.Unschedulable, failureReasons...)
}
return nil
}
从上面的源码中不难看出,调度器(实际上是 Schedule thread )首先会在 Pre filter 阶段计算出待调度 pod 所需要的资源,具体讲就是从 Pod Spec 中分别计算初始容器和工作容器requests之和,并取其较大者,特别地,对于像 Kata-container 这样微虚机,其自身的虚拟化开销相比于容器来说是不能忽略不计的,所以还需要加上虚拟化本身的资源开销,计算出的结果存入到缓存中,在紧接着的 Filter 阶段,会遍历所有节点过滤出符合符合条件的节点。
实际上在过滤出所有符合条件的节点以后,如果当前满足的条件的节点只有一个,那么该 pod 随后将被调度到该结点。但是更多的情况下,此时过滤之后符合条件的结点往往有多个,这时候就需要进入 Score 阶段,依次对这些结点进行打分( Score )。而打分本身也是包括多个维度通过内置 plugin 的形式综合评判的。值得注意的是,前面我们定义的 pod 的requests和limits参数也会直接影响到NodeResourcesLeastAllocated算法最终的计算结果。源码如下:
func leastResourceScorer(resToWeightMap resourceToWeightMap) func(resourceToValueMap, resourceToValueMap, bool, int, int) int64 {
return func(requested, allocable resourceToValueMap, includeVolumes bool, requestedVolumes int, allocatableVolumes int) int64 {
var nodeScore, weightSum int64
for resource, weight := range resToWeightMap {
resourceScore := leastRequestedScore(requested[resource], allocable[resource])
nodeScore += resourceScore * weight
weightSum += weight
}
return nodeScore / weightSum
}
}
...
func leastRequestedScore(requested, capacity int64) int64 {
if capacity == 0 {
return 0
}
if requested > capacity {
return 0
}
return ((capacity - requested) * int64(framework.MaxNodeScore)) / capacity
}
可以看到在NodeResourcesLeastAllocated算法中,对于同一个 pod ,目标结点的资源越充裕,那么该结点的得分也就越高。换句话说,同一个 pod 更倾向于调度到资源充足的结点。需要注意的是,实际上在创建 pod 的过程中,一方面, K8s 需要拨备包含 CPU 和内存在内的多种资源。每种资源都会对应一个权重(对应源码中的 resToWeightMap 数据结构),所以这里的资源均衡是包含 CPU 和内存在内的所有资源的综合考量。另一方面,在 Score 阶段,除了NodeResourcesLeastAllocated算法以外,调用器还会使用到其他算法(例如InterPodAffinity)进行分数的评定。
注:在 K8s 调度器中,会把调度过程分为若干个阶段,即 Pre filter, Filter, Post filter, Score 等。在 Pre filter 阶段,用于选择符合 Pod Spec 描述的 Nodes 。
QoS 是如何影响 K8s 调度决策的?
QOS 作为 K8s 中一种资源保护机制,其主要是针对不可压缩资源比如的内存的一种控制技术,比如在内存中其通过为不同的 pod 和容器构造 OOM 评分,并且通过内核的策略的辅助,从而实现当节点内存资源不足的时候,内核可以按照策略的优先级,优先 kill 掉哪些优先级比较低(分值越高优先级越低)的pod。相关源码如下:
func GetContainerOOMScoreAdjust(pod *v1.Pod, container *v1.Container, memoryCapacity int64) int {
if types.IsCriticalPod(pod) {
// Critical pods should be the last to get killed.
return guaranteedOOMScoreAdj
}
switch v1qos.GetPodQOS(pod) {
case v1.PodQOSGuaranteed:
// Guaranteed containers should be the last to get killed.
return guaranteedOOMScoreAdj
case v1.PodQOSBestEffort:
return besteffortOOMScoreAdj
}
// Burstable containers are a middle tier, between Guaranteed and Best-Effort. Ideally,
// we want to protect Burstable containers that consume less memory than requested.
// The formula below is a heuristic. A container requesting for 10% of a system's
// memory will have an OOM score adjust of 900. If a process in container Y
// uses over 10% of memory, its OOM score will be 1000. The idea is that containers
// which use more than their request will have an OOM score of 1000 and will be prime
// targets for OOM kills.
// Note that this is a heuristic, it won't work if a container has many small processes.
memoryRequest := container.Resources.Requests.Memory().Value()
oomScoreAdjust := 1000 - (1000*memoryRequest)/memoryCapacity
// A guaranteed pod using 100% of memory can have an OOM score of 10. Ensure
// that burstable pods have a higher OOM score adjustment.
if int(oomScoreAdjust) < (1000 + guaranteedOOMScoreAdj) {
return (1000 + guaranteedOOMScoreAdj)
}
// Give burstable pods a higher chance of survival over besteffort pods.
if int(oomScoreAdjust) == besteffortOOMScoreAdj {
return int(oomScoreAdjust - 1)
}
return int(oomScoreAdjust)
}
总结
Kubernetes 作为一个具有良好移植和扩展性的开源平台,用于管理容器化的工作负载和服务。 Kubernetes 拥有一个庞大且快速增长的生态系统,已成为容器编排领域的事实标准。但是也不可避免地引入许多复杂性。而 KubeSphere 作为国内唯一一个开源的 Kubernetes(K8s)发行版,极大地降低了使用 Kubernetes
的门槛。借助于 KubeSphere 平台,原先需要通过后台命令行和 yaml 文件管理的系统配置,现在只需要在简介美观的 UI 界面上轻松完成。本文从云原生应用部署阶段requests和limits的设置问题其入,分析了相关 K8s 底层的工作原理以及如何通过 KubeSphere 平台简化相关的运维工作。
参考文献
- https://learnk8s.io/setting-cpu-memory-limits-requests
- https://kubernetes.io/docs/tasks/configure-pod-container/quality-service-pod/
- https://docs.oracle.com/cd/E13150_01/jrockit_jvm/jrockit/jrdocs/refman/optionX.html
- https://kubesphere.com.cn/forum/d/1155-k8s
- https://kubernetes.io/docs/tasks/administer-cluster/out-of-resource/
- https://kubernetes.io/docs/concepts/policy/limit-range/
- https://www.kernel.org/doc/Documentation/scheduler/sched-bwc.txt
- https://www.kernel.org/doc/Documentation/scheduler/sched-design-CFS.txt
- https://access.redhat.com/documentation/en-us/red_hat_enterprise_linux/6/html/resource_management_guide/sec-cpu
- https://medium.com/omio-engineering/cpu-limits-and-aggressive-throttling-in-kubernetes-c5b20bd8a718
目录