






发布于:2018-03-27
OpenPitrix Insight





云计算在今天已经被绝大多数的企业所采用,具知名云服务厂商 RightScale 最近的调查显示,已经有越来越多的厂商采用多云管理。客户有太多的理由来选择多云管理了,其中最大的原因莫过于采用单一的供应商,会导致被锁定。因此,如何管理多云环境,并在多云的环境下进行自动化,正成为众多企业的刚需,而在这其中,应用程序的管理显得尤为的重要。进一步讲,颇具挑战的是创建一个一站式的应用管理平台,来管理不同类型的应用程序,其中包括传统的应用(或者称之为单体应用,或者传统的主从、分片、peer-to-peer 架构的企业分布式应用)、微服务应用、以及近来发展迅猛的 Serverless 应用等,OpenPitrix 就是为了解决这些问题而生的。用一句话来描述 OpenPitrix:
OpenPitrix 是一款开源项目,用来在多云环境下打包、部署和管理不同类型的应用,包括传统应用、微服务应用以及 Serverless 应用等,其中云平台包括 AWS、Azure、Kubernetes、QingCloud、OpenStack、VMWare 等。
微服务,即众所周知的微服务架构,这是程序设计的必然趋势,企业创建新的应用时选择的主要方式。另外,开源项目 Kubernetes 已经成为事实上的编排平台的领导者,其在自动化部署、扩展性、以及管理容器化的应用有着独特的优势。但是,仍然有大量的传统遗留应用用户想在毋须改变其架构的情况下迁入到云平台中,而且对很多用户来讲,采用微服务架构,或者是 Serverless 架构还是比较遥远的事情,所以,我们需要帮助这些用户将他们的传统应用迁入到云计算平台中,这也是 OpenPitrix 很重要的一个功能。
在2017年3月27日,QingCloud 发布 AppCenter,一款旨在为传统企业应用开发商和云用户之间架设友好桥梁的平台,该平台最大的亮点在于其可以让开发者以极低的学习成本就可以将传统的应用程序移植到 QingCloud 中运行,并且具有云计算的所有特性,如敏捷性、伸缩性、稳定性、监控等。通常,一位开发者只需花上几个小时就可以理解整个工作流程,然后,再花一到两周的时间(这具体要取决于应用的复杂性)将应用移植到云平台中。该平台上线之后一直颇受用户的青睐和夸赞,但有一些用户提出更多的需求,希望将之部署到他们内部来管理他们的多云环境。为了满足用户的需求,QingCloud 将之扩展,即在多云的环境下管理多种类型的应用程序,并且采用开源的方法来进行项目的良性发展。
俗语有云:“知易行难”,尽管 OpenPitrix 原始团队在云计算应用开发有着足够丰富的经验,并成功的开发出了稳定的商业化产品:AppCenter,要知道,等待在前方的依然有很多困难要克服。OpenPitrix 从一开始就是以开源的方式来进行,并且在2017年的8月份在 GitHub 上创建了组织和项目,一直到2018年2月24日才写下第一行功能代码,在此期间,团队的所有成员都在思考系统的每个关键点,这些讨论的细节均可在 GitHub 上公开访问。
以上便是 OpenPitrix 项目的来龙去脉介绍,接下来会解释一些详细的功能和设计细节。
主要的功能
OpenPitrix 所希望实现的功能包括以下内容:
- 支持多个云平台,如 AWS、Azure、Kubernetes、QingCloud、OpenStack、VMWare 等等;
- 云平台的支持是高度可扩展和插拔的;
- 支持多种应用程序的类型:传统应用、微服务应用、Serverless 应用;
- 应用程序的支持也是高度可扩展的,这也就意味着无论将来出现哪种新的应用程序类型,OpenPitrix 平台都可以通过添加相应的插件来支持它;
- 应用程序的仓库是可配置的,这也就意味着由 OpenPitrix 所驱动的商店,其应用均是可以用来交易的;
- 应用程序库的可见性是可配置的,包括公开、私有或仅让某特定的一组用户可访问,由 OpenPitrix 所驱动的市场,每个供应商都能够操作属于她/他自己的应用商店。
用户场景实例
OpenPitrix 典型的用户场景有:
- 某企业是采用了多云的系统(包括混合云),要实现一站式的应用管理平台,从而实现应用的部署和管理;
- 云管平台(CMP)可以将 OpenPitrix 视为其其中一个组件,以实现在多云环境下管理应用;
- 可以作为 Kubernetes 的一个应用管理系统。OpenPitrix 和 Helm 有着本质上的不同,虽然 OpenPitrix 底层用了 Helm 来部署 Kubernetes 应用,但 OpenPitrix 着眼于应用的全生命周期管理,比如在企业中,通常会按照应用的状态来分类,如开发、测试、预览、生产等;甚至有些组织还会按照部门来归类,而这是 Helm 所没有的。
架构概览
OpenPitrix 设计的最根本的思想就是解耦应用和应用运行时环境(此处使用运行时环境代替云平台,下同),如下图所示。应用程序能够运行在哪个环境,除了需要匹配 provider 信息之外,还需要匹配应用所在仓库的选择器 (selector) 和运行时环境的标签 (label),即当某个最终用户从商店里选择了某个具体的应用,然后尝试部署它时,系统会自动选择运行时环境。如果有多个运行时环境可以运行此应用的话,则系统会弹出相应的对话框来让用户自行选择,更多设计细节请参考 OpenPitrix 设计文档。
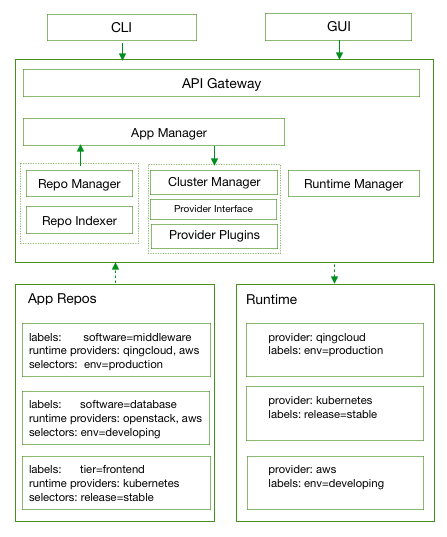
应用程序仓库子系统
如上面架构概览图所示,仓库子系统分为三大组件:仓库管理 (Repo Manager)、仓库索引 (Repo Indexer)、仓库存储 (App Repo);其中仓库管理包括仓库服务 (Repo Service) 和其后端的数据库 (Repo DB),架构图如下所示。用户创建应用仓库时需配置的信息如:URL、凭证、是否可见等,通常是系统管理人员或开发者为平台创建仓库。仓库索引的守护进程会周期性地扫描新增的仓库、现有仓库的任何更新,并将信息更新到应用管理服务的数据库中。我们可以看出,仓库的存储是独立于特定的 OpenPitrix 平台的,所以,仓库存储的应用可以共享给任何基于 OpenPitrix 的应用管理平台使用。更多设计详情请参考 OpenPitrix 仓库子系统设计。

由仓库组织的应用,都可以作为独立资产由基于 OpenPitrix 的商店来售卖。
如何将传统的应用迁移到多云的环境
首先要申明的是,OpenPitrix 不会特别地去区分多云和混合云之间的差别,在本文中,在没有特别提示的情况下,多云意味着多个云环境,无论它们是公共云还是私有云,还是来自相同或不同的供应商。
规范
很显然,我们将大量借助 QingCloud AppCenter 的经验来实现在多云环境下“云化”传统应用,这其中包括规范在内。为了简单起见,我们在这里展示了一个不完整的 ZooKeeper 云化规范版本,如下所示,完整版本请参考 AppCeneter 示例,该规范很容易理解,文件 cluster.json.tmpl 定义了 ZooKeeper 集群信息,如名称、描述、多少节点(每个节点的 CPU、内存、存储、镜像、生命周期等),双花括号中的变量来自最终用户从 UI 输入的信息,这些变量是由文件config.json定义的。ZooKeeper 应用开发者将这两个文件打包上传到 OpenPitrix 平台,最终用户在部署应用的时候输入必要的信息、点击部署按钮即可。这个应用程序包(还包含语言文件)如同镜像是虚拟机的模板一样,它是一个应用程序的模板,只是它相比镜像更为的复杂罢了,因为它可能包括多个镜像,而且要定义应用程序集群的整个生命周期,还有,它还要支持自定义的监控、健康监测等等更多的功能。正如我们所看到的,开发者将传统应用移植到云平台中除了几个说明文件毋须任何的编码。
cluster.json.tmpl for ZooKeeper
{ "name": {{cluster.name}}, "description": {{cluster.description}}, "subnet": {{cluster.subnet}}, "nodes": [{ "container": { "type": "kvm", "zone": "pek3a", "image": "img-svm7yple" }, "count": {{cluster.zk_node.count}}, "cpu": {{cluster.zk_node.cpu}}, "memory": {{cluster.zk_node.memory}}, "volume": { "size": {{cluster.zk_node.volume_size}} }, "services": { "start": { "cmd": "/opt/zookeeper/bin/zkServer.sh start;/opt/zookeeper/bin/rest.sh start" }, "stop": { "cmd": "/opt/zookeeper/bin/rest.sh stop;/opt/zookeeper/bin/zkServer.sh stop" } } }] }
config.json for ZooKeeper
{ "type": "array", "properties": [{ "key": "cluster", "description": "ZooKeeper release 3.4.9 cluster properties", "type": "array", "properties": [{ "key": "name", "label": "Name", "description": "The name of the ZooKeeper service", "type": "string", "default": "ZooKeeper", "required": "no" }, { "key": "description", "label": "Description", "description": "The description of the ZooKeeper service", "type": "string", "default": "", "required": "no" }, { "key": "subnet", "label": "Subnet", "description": "Choose a subnet to join", "type": "string", "default": "", "required": "yes" }, { "key": "zk_node", "label": "ZooKeeper Node", "description": "role-based node properties", "type": "array", "properties": [{ "key": "cpu", "label": "CPU", "description": "CPUs of each node", "type": "integer", "default": 1, "range": [ 1, 2, 4, 8 ], "required": "yes" }, { "key": "memory", "label": "Memory", "description": "memory of each node (in MiB)", "type": "integer", "default": 2048, "range": [ 1024, 2048, 4096, 8192, 16384, 32768 ], "required": "yes" }, { "key": "count", "label": "Node Count", "description": "Number of nodes for the cluster to create", "type": "integer", "default": 3, "range": [ 1, 3, 5, 7, 9 ], "required": "yes" }, { "key": "volume_size", "label": "Volume Size", "description": "The volume size for each node", "type": "integer", "default": 10, "required": "yes" }] }] }] }
架构
整个系统中最具挑战性的工作就是如何将上述的一套标准的传统应用软件包无需任何修改就能部署到多个云平台中,因为传统的应用均是基于虚拟机而非容器的。OpenPitrix 设计团队经过了激烈的讨论,最后总结出如下几个原则:
- OpenPitrix 自身是可以部署到任何地方的。因此,该平台必须支持最终用户同时将应用程序部署到公共云和私有云中,这意味着 OpenPitrix 从架构必须支持能够通过公共互联网部署应用程序;
- 针对每个 IaaS 平台供应商的架构是一致的;
- 最终用户部署应用程序毋须任何麻烦的配置,这意味着对于最终用户而言,一切都是透明的,例如元数据服务的初始化。
经过反复的讨论后,我们提出了以下解决方案。首先解释一下架构中出现的一些术语。
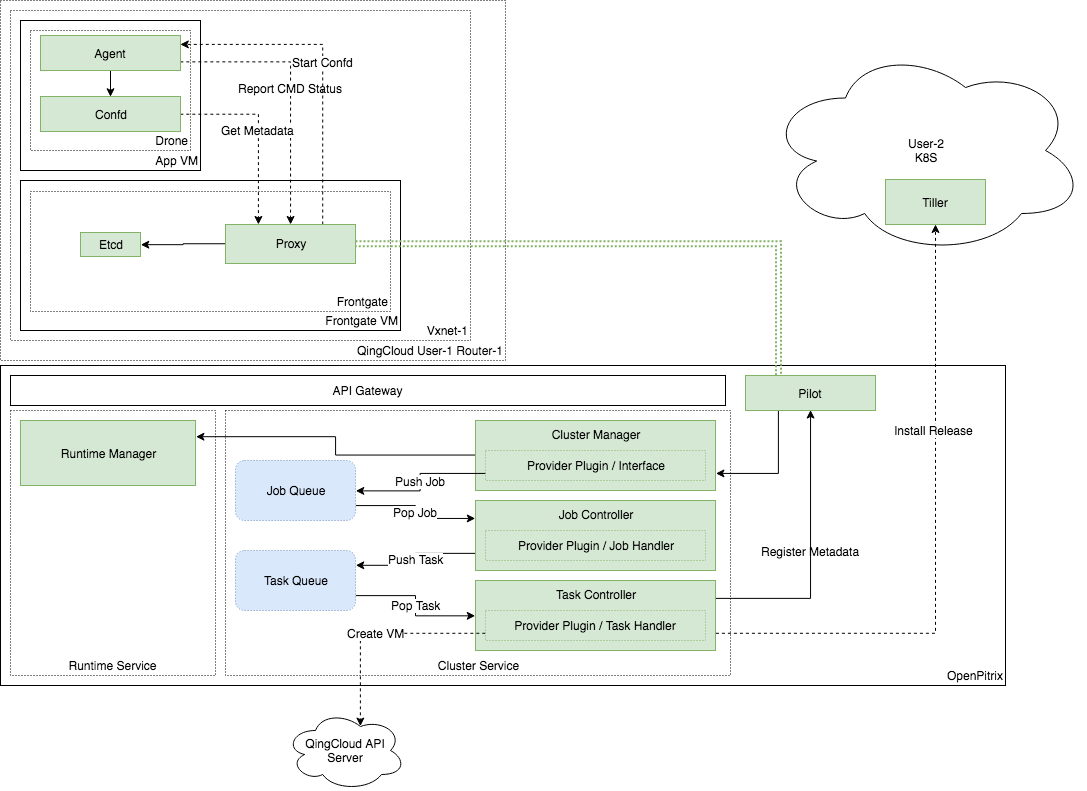
- Drone:该组件由 agent 和 confd 所构成,Confd 是自动配置 app 实例的守护进程,agent 负责和 Frontgate 的通信,例如来自最终用户发来的指令。agent 也会负责根据应用的状态启动和停止 confd。Drone 是预先安装到应用程序所在的每一个镜像中。
- Frontgate:该组件包含 proxy 和 etcd,Etcd 是后端的存储,存储集群的信息包括集群名称、描述、多少节点、由最终用户发来的指令等。Proxy 连接 Pilot 和 Drone 的 agent,因为虚拟机是运行在 VPC 中,Pilot 无法和 Drone 直接进行通信,所以需要在它们二者之间设置一个 proxy。在有应用运行的 VPC 中会存在一个 Frontgate,这个 VPC 内的所有应用集群共享这个 Frontgate,这个 Frontgate 是当最终用户第一次部署应用程序时,系统自动创建的,且 Frontgate 对最终用户不可见。
- Pilot:接受来自集群服务的指令和信息的组件,如创建集群等,并可以传递指令给 Frontgate,它还接收来自 Frontgate 上传上来的信息。
毫无疑问,工作流程很复杂。我们以部署一个应用程序为例来进行简要的说明,一般步骤如下:
- 最终用户发送请求到 API 网关,API 网关会将之转发给相应的服务,如集群服务;
- 集群服务收到请求之后,将之放到 job 队列,job 控制器收到后将其分解成 task,然后放到 task 队列;
- Task 控制器将 Task 从队列中提出,然后去调用特定的云平台 API,创建集群资源如主机;
- 集群服务同样会给 Pilot 发送集群的元数据;
- Pilot 转发信息给 Frontgate 的 proxy,然后 proxy 会将信息注册到后端的 Etcd;
- 应用程序镜像内部的 Drone 的 Confd 会监测 etcd 的更新,然后自动更新应用配置;
- 最后,Drone 中的 agent 为用户启动应用。
整个流程,如下图所示:
应用程序镜像
正如上面所阐述的,传统应用通常是部署到虚拟机中的,而微服务应用往往是进行容器化的。如果我们使用虚拟机来支持传统应用部署到多云环境中的话,会遇到非常大的挑战。这意味着应用的开发者或供应商在每一个环境中都需要上传或创建镜像,而这在现实中往往很难行得通,尤其是公有云供应商提供很多的 region 和 zone。鉴于此种情况,我们选择了在虚拟机中运行容器的方式来解决此问题,可以建立集中的容器镜像仓库,需要运行时直接拉到云平台中的虚拟机中即可。此种方式也有弊端,那就是在网络不好的地方,拉容器镜像就是一个大的问题,如果下载容器镜像的时间过长,对于用户的体验和耐心都是极大的挑战。要解决此问题,在每个云环境部署缓存或 mirror 是非常好的选择。第二个问题是开发人员需要知道 Docker,这似乎不是一个大问题,因为在我看来,掌握 Docker 是当今开发人员的基本技能。
但是,我们依然需要支持直接在 VM 中安装应用程序软件,并将 VM 分发到每个云环境中,原因如下。
- 有一些应用需要定制化 Linux 内核;
- 开发者没有掌握 Docker 技术,或者说因为额外的学习或开发成本,开发者并不愿意用 Docker 的方式将传统应用移植到云环境中;
- 最终用户没有意愿去创建一个诸如 Kubernetes 这样的容器编排集群去部署一个传统应用,或者是用户没有 Kubernetes 环境。
在第一个版本中,会在虚拟机中使用 Docker 的方式来解决应用程序镜像的分发问题,在下个版本中,将支持直接在 VM 中安装应用程序软件。
如何支持多种类型的应用
正如我们开始所说的,OpenPitrix 是支持多种类型的应用程序。当一个用户开始部署一个应用的时候,系统会自动识别应用类型并选择相应的插件去创建应用集群。我们用 provider interface 和 provider plugin 来支持不同类型应用以及将来可能出现的未知应用类型。系统目前有两大类应用类型:基于虚机的和基于容器的,前者是支持传统应用上云,这个我们已经在上一章节解释过了,现在我们解释一下 OpenPitrix 如何支持日益流行的基于互联网规模的应用程序:微服务和 Serverless。对于 OpenPitrix 的第一个版本,没有打算支持 Serverless,我们认为 Serverless 应用还没有标准,而且也没有看清楚谁将赢得最后的胜利。市场上没有与其他主要供应商兼容的产品或服务。那么这样的局面就是家家都是标准的制定者,所以,OpenPitrix 团队决定第一个版本暂时先不支持将 Serverless 应用部署到多云环境, 并持续关注 Serverless 最新标准的进展。
另外,在容器的编排方面,开源项目 Kubernetes 已经赢得了胜利,因此,OpenPitrix 会支持 Kubernetes。Helm 是一个非常不错的 Kubernetes 包管理器,在第一版 OpenPitrix 中,我们使用 Helm 作为 Kubernetes 应用程序的部署工具,在下一版或许会直接采用 Kubernetes 的应用编排格式。
如下图所示,我们将 Helm 的客户端打包到 OpenPitrix 中,另外 Helm 的服务端组件 Tiller 也会作为 OpenPitrix 的组件,这样作为 OpenPitrix 的最终用户,根本就不需要学习任何关于 Helm 的内容,就可以将应用部署到 Kubernetes 中,然而,在撰写本文时,Helm 服务对于 Kubernetes 多集群的管理还尚待改善,详情见 issues 1586和1918,因此,在问题解决之前,我们会要求用户将 Tiller 安装到每个 Kubernetes 集群中。当最终用户配置 Kubernetes 集群时,系统将自动配置并测试 OpenPitrix 和 Kubernetes 集群之间的连通性。然后,用户就可以将 Kubernetes 应用程序部署到任意集群中了。

总结
我们规划未来的 OpenPitrix 会增加更多的功能,例如:
- 针对开发者的工作台,可以让开发者在此以极简的方式开发应用;
- 开发者可以查看使用其应用程序的所有状态包括统计信息;
- 计量计费功能
- 各种报表功能
- ……
OpenPitrix 将会逐步发展为多云环境下应用程序管理系统的全方位的解决方案。
目录