












帐号无法登录
KubeSphere 安装时会自动创建 admin/P@88w0rd 默认帐户,ks-controller-manager 将用户状态同步到 openldap、Jekins 之后会加密帐户密码,在此之后帐户状态会被转换为 Active 帐户才可以正常登录。
下面是帐户无法登录时,一些常见的问题:
account not active
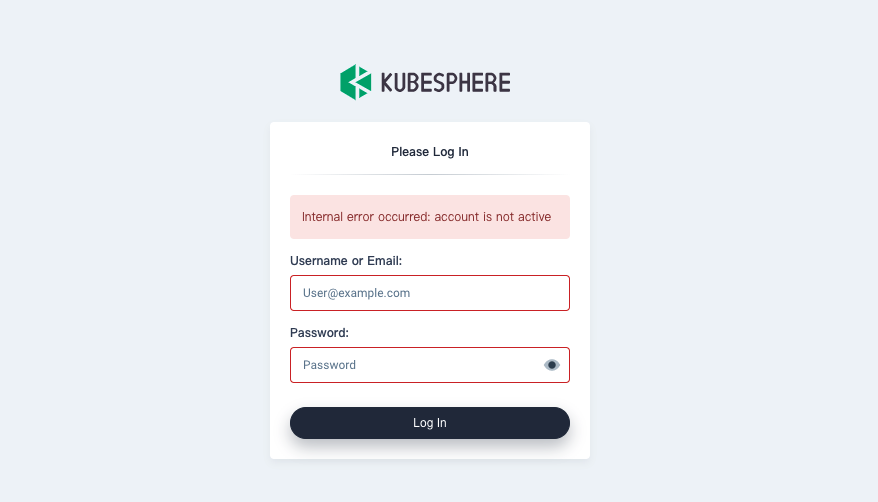
您可以通过以下命令来检查帐户状态:
$ kubectl get users
NAME EMAIL STATUS
admin admin@kubesphere.io Active
检查 ks-controller-manager 是否正常运行,是否有异常日志:
kubectl -n kubesphere-system logs -l app=ks-controller-manager
K8s 1.19 中 admission webhook 无法正常工作
K8s 1.19 使用了 Golang 1.15 进行编译,需要更新 admission webhook 用到的证书,该问题导致 ks-controller admission webhook 无法正常使用。
相关错误日志:
Internal error occurred: failed calling webhook “validating-user.kubesphere.io”: Post “https://ks-controller-manager.kubesphere-system.svc:443/validate-email-iam-kubesphere-io-v1alpha2-user?timeout=30s”: x509: certificate relies on legacy Common Name field, use SANs or temporarily enable Common Name matching with GODEBUG=x509ignoreCN=0
相关 issue 和解决方式 https://github.com/kubesphere/kubesphere/issues/2928
ks-controller-manager 无法正常工作
ks-controller-manager 依赖 openldap、Jenkins 这两个有状态服务,当 openldap 或 Jekins 无法正常运行时会导致 ks-controller-manager 一直处于 reconcile 状态。
可以通过以下命令检查 openldap 和 Jeknins 服务是否正常:
kubectl -n kubesphere-devops-system get po | grep -v Running
kubectl -n kubesphere-system get po | grep -v Running
kubectl -n kubesphere-system logs -l app=openldap
相关错误日志:
failed to connect to ldap service, please check ldap status, error: factory is not able to fill the pool: LDAP Result Code 200 "Network Error": dial tcp: lookup openldap.kubesphere-system.svc on 169.254.25.10:53: no such host
Internal error occurred: failed calling webhook “validating-user.kubesphere.io”: Post https://ks-controller-manager.kubesphere-system.svc:443/validate-email-iam-kubesphere-io-v1alpha2-user?timeout=4s: context deadline exceeded
解决方式
您需要先恢复 openldap、Jenkins 这两个服务并保证网络的连通性,重启 ks-controller-manager 后会立即触发 reconcile(当无法连接到 openldap 或 Jenkins 时重试间隔会递增)。
kubectl -n kubesphere-system rollout restart deploy ks-controller-manager
使用了错误的代码分支
如果您使用了错误的 ks-installer 版本,会导致安装之后各组件版本不匹配。
通过以下方式检查各组件版本是否一致,正确的 image tag 应该是 v3.0.0。
kubectl -n kubesphere-system get deploy ks-installer -o jsonpath='{.spec.template.spec.containers[0].image}'
kubectl -n kubesphere-system get deploy ks-apiserver -o jsonpath='{.spec.template.spec.containers[0].image}'
kubectl -n kubesphere-system get deploy ks-controller-manager -o jsonpath='{.spec.template.spec.containers[0].image}'
帐号或密码错误
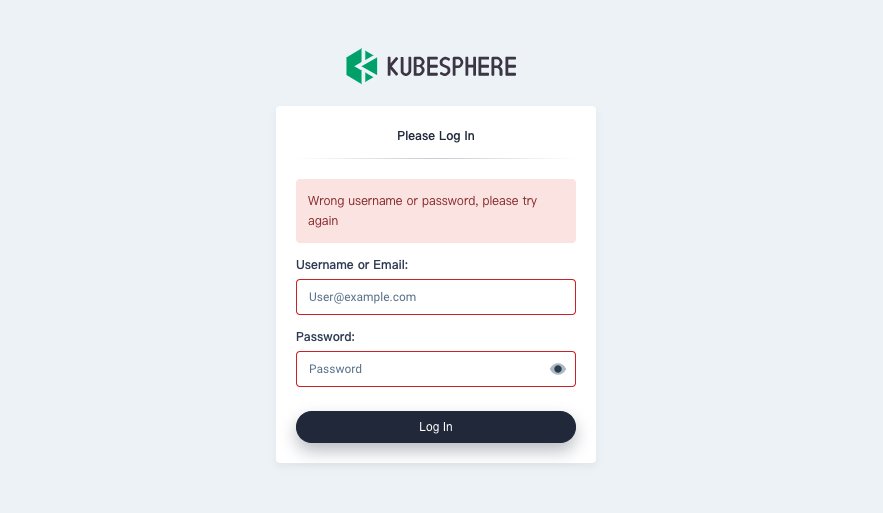
ks-console 和 ks-apiser 需要借助 Redis 在多个副本之间共享数据,当 Redis 服务异常时会导致 ks-console 多个副本之间无法共享密码加密传输时使用的 salt。
通过以下命令检查帐号密码是否正确:
curl -u <USERNAME>:<PASSWORD> "http://`kubectl -n kubesphere-system get svc ks-apiserver -o jsonpath='{.spec.clusterIP}'`/api/v1/nodes"
Redis 异常
您可以通过以下命令检查 Redis 服务是否正常:
kubectl -n kubesphere-system logs -l app=ks-console
kubectl -n kubesphere-system get po | grep -v Running
# High Availability
kubectl -n kubesphere-system exec -it redis-ha-server-0 redis-cli info replication
kubectl -n kubesphere-system exec -it redis-ha-server-0 -- sh -c 'for i in `seq 0 2`; do nc -vz redis-ha-server-$i.redis-ha.kubesphere-system.svc 6379; done'
kubectl -n kubesphere-system logs -l app=redis-ha-haproxy
kubectl -n kubesphere-system logs -l app=redis-ha
# Single Replica
kubectl -n kubesphere-system logs -l app=redis
相关错误日志:
1344:C 17 Sep 2020 17:13:18.099 # Failed opening the RDB file dump.rdb (in server root dir /data) for saving: Stale file handle 1:M 17 Sep 2020 17:13:18.198 # Background saving error 1:M 17 Sep 2020 17:13:24.014 * 1 changes in 3600 seconds. Saving… 1:M 17 Sep 2020 17:13:24.015 * Background saving started by pid 1345 1345:C 17 Sep 2020 17:13:24.016 # Failed opening the RDB file dump.rdb (in server root dir /data) for saving: Stale file handle 1:M 17 Sep 2020 17:13:24.115 # Background saving error
E0909 07:05:22.770468 1 redis.go:51] unable to reach redis host EOF
[WARNING] 252/094143 (6) : Server check_if_redis_is_master_0/R0 is DOWN, reason: Layer7 timeout, info: " at step 5 of tcp-check (expect string ‘10.223.2.232’)", check duration: 1000ms. 2 active and 0 backup servers left. 0 sessions active, 0 requeued, 0 remaining in queue. [WARNING] 252/094143 (6) : Server check_if_redis_is_master_0/R1 is DOWN, reason: Layer7 timeout, info: " at step 5 of tcp-check (expect string ‘10.223.2.232’)", check duration: 1000ms. 1 active and 0 backup servers left. 0 sessions active, 0 requeued, 0 remaining in queue. [WARNING] 252/094143 (6) : Server check_if_redis_is_master_0/R2 is DOWN, reason: Layer7 timeout, info: " at step 5 of tcp-check (expect string ‘10.223.2.232’)", check duration: 1000ms. 0 active and 0 backup servers left. 0 sessions active, 0 requeued, 0 remaining in queue. [ALERT] 252/094143 (6) : backend ‘check_if_redis_is_master_0’ has no server available!
解决方式
您需要先恢复 Redis 服务,保证其正常运行并且pod之间网络可以正常联通,稍后您可以重启 ks-console 以立即同步副本之间的数据。
kubectl -n kubesphere-system rollout restart deploy ks-console
 上一篇
上一篇

页面内容