






You are viewing documentation for KubeSphere version:v3.0.0
KubeSphere v3.0.0 documentation is no longer actively maintained. The version you are currently viewing is a static snapshot. For up-to-date documentation, see the latest version.






KubeSphere DevOps Data Migration during Upgrade
When you upgrade KubeSphere from v2.1 to v3.0, the issues you may encounter in DevOps are mainly caused by the changes in the DevOps architecture. This document illustrates the changes in the DevOps architecture and explores data migration plans and risks.
DevOps Architecture Comparison
DevOps in KubeSphere v2.1
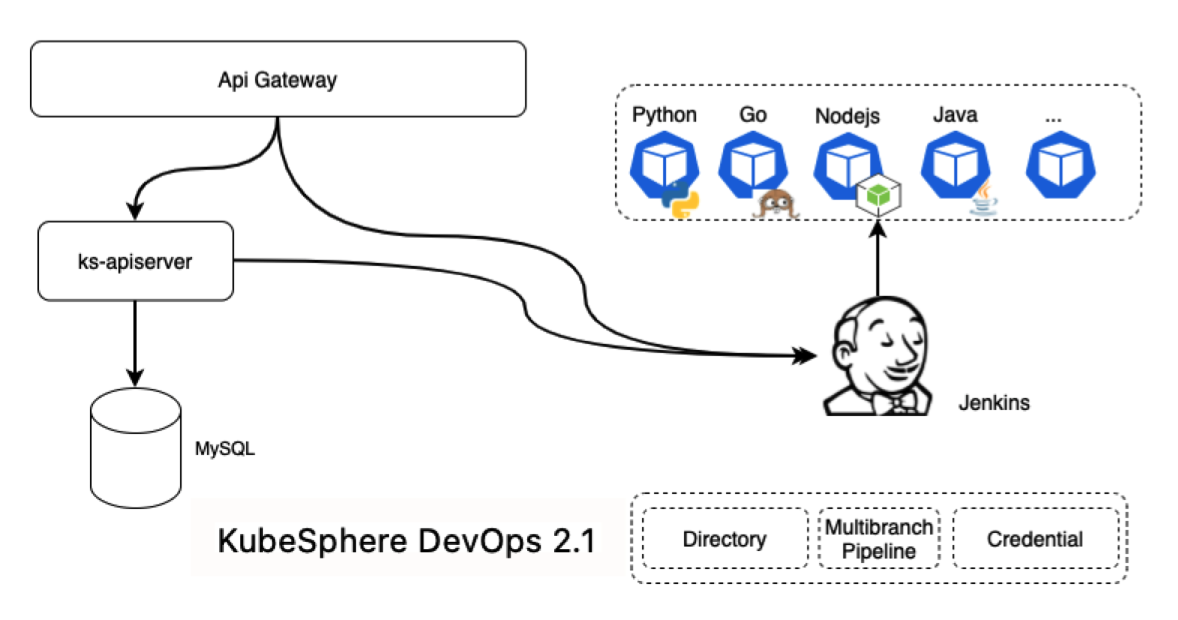
In KubeSphere v2.1, the DevOps data are stored in Jenkins, while MySQL in KubeSphere stores authorization information and corresponding relations among projects, pipelines, and users. Frontend users make calls to the Api Gateway to get authentication from ks-apiserver and then connect to Jenkins.
Another special type is /kapis/jenkins.kubesphere.io, which is directly passed to Jenkins through the Api Gateway and mainly used when archive files are downloaded.
DevOps in KubeSphere v3.0
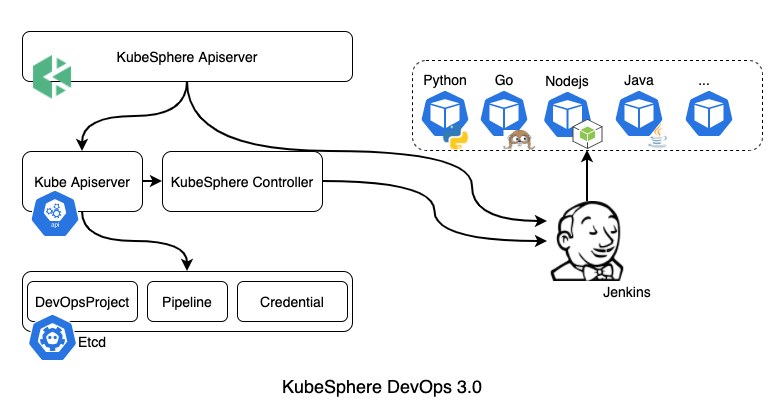
In KubeSphere v3.0, the DevOps data are stored in CustomResourceDefinitions (CRDs). The data in the CRDs are synchronized to Jenkins in an one-way direction, and any previous data with the same name will be overwritten. There are mainly two types of operation - creation and triggering.
Creation mainly involves three CRD types, including DevOps projects, pipelines and credentials. Users make calls at the frontend to the interface of ks-apiserver to create resources and store them in etcd, and then ks-controller-manager keeps synchronizing those objects to Jenkins. Triggering mainly entails instant actions, including running a pipeline and reviewing a pipeline. Users make calls at the frontend to ks-apiserver, and then, after data conversion, directly make calls to the Jenkins API.
Data Migration Logic
When you upgrade KubeSphere from v2.1 to v3.0, the process of data migration follows the steps shown below:
- Retrieve information about DevOps directories from MySQL.
- Retrieve information about pipelines and credentials from Jenkins.
- Serialize the above information into a YAML file.
- Back up the YAML resource object to the MinIO object storage.
- Use the
kubectl applycommand to apply these pipeline resources. - Authorizations migration.
Data comparison before and after the migration:
| Resources | v2.1 | v3.0 |
|---|---|---|
| DevOps projects | MySQL | CRD |
| Pipelines | Jenkins | CRD |
| Credentials | Jenkins | CRD |
| Authorizations | MySQL | CRD |
Warning
You must back up the data in advance because the data in Jenkins will be overwritten by ks-controller-manager once the CRDs are created during data migration. You can use Velero to make a PVC-level backup, or back up the
/var/jenkins_home directory of the Jenkins Pod directly.Data Migration Plans and Risks
For the pipelines created on the KubeSphere DevOps page, migration can be carried out as normal. However, the pipeline configurations directly made on the Jenkins dashboard might get lost during the migration.
Migration through a Job
This plan applies to the scenario where DevOps operations are only performed on the KubeSphere DevOps page. You can upgrade KubeSphere directly, and if there is no DevOps resources available after the upgrade, rerun the upgrade.
No migration for the previous data
KubeSphere DevOps is compatible with most Jenkins configurations, while some on the Jenkins dashboard are not supported by KubeSphere DevOps as shown below:
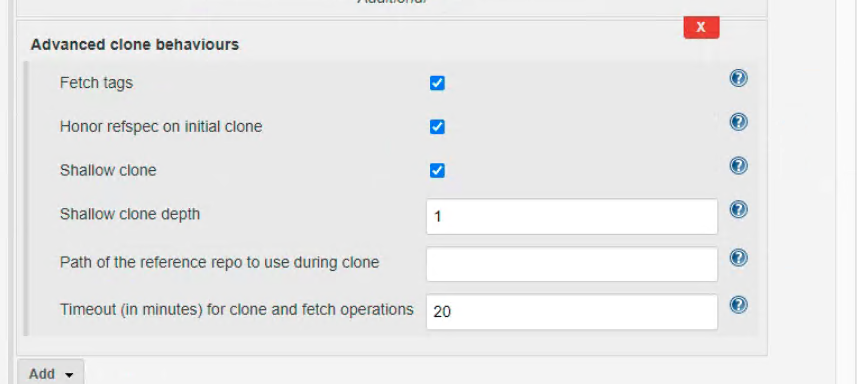
These configurations will be cleared after data migration. Even if they are added again after the data migration, they will still be cleared when you edit a pipeline next time.
Note
Generally speaking, you cannot specify these configurations in a Jenkinsfile as they are not part of the logic as a pipeline runs.
If you have specific needs for these configurations, you can keep your previous data unmigrated and manage new pipelines on the KubeSphere DevOps page.
Warning
Do not create pipelines with the same name under one DevOps project, or the data in Jenkins will be overwritten.
Partial migration
If you only have few configurations to be specified on the Jenkins dashboard, you can use KubeSphere DevOps to manage pipelines directly. For these users, they can make a backup first and then migrate part of the data by using a Job while fixing pipelines with special configurations later.
If there is a high requirement for availability, users can reuse the previous DevOps project and manually create a new pipeline with a different name to run it for testing. If the new pipeline runs successfully, users can delete the previous pipeline.
Info
You can use the command kubectl get devopsprojects --all-namespaces and kubectl get pipelines --all-namespaces to check the migration results.
You can also use the following command to rerun the Job for migration.
kubectl -n kubesphere-system get job ks-devops-migration -o json | jq 'del(.spec.selector)' | jq 'del(.spec.template.metadata.labels)' | kubectl replace --force -f -
 Previous
Previous

What’s on this Page