






You are viewing documentation for KubeSphere version:v3.0.0
KubeSphere v3.0.0 documentation is no longer actively maintained. The version you are currently viewing is a static snapshot. For up-to-date documentation, see the latest version.











Node Management
Kubernetes runs your workloads by placing containers into Pods to run on nodes. A node may be a virtual or physical machine, depending on the cluster. Each node contains the services necessary to run Pods, managed by the control plane. For more information about nodes, see the official documentation of Kubernetes.
This tutorial demonstrates what a cluster administrator can view and do for nodes within a cluster.
Prerequisites
You need an account granted a role including the authorization of Clusters Management. For example, you can log in to the console as admin directly or create a new role with the authorization and assign it to an account.
Node Status
Cluster nodes are only accessible to cluster administrators. Some node metrics are very important to clusters. Therefore, it is the administrator’s responsibility to watch over these numbers and make sure nodes are available. Follow the steps below to view node status.
-
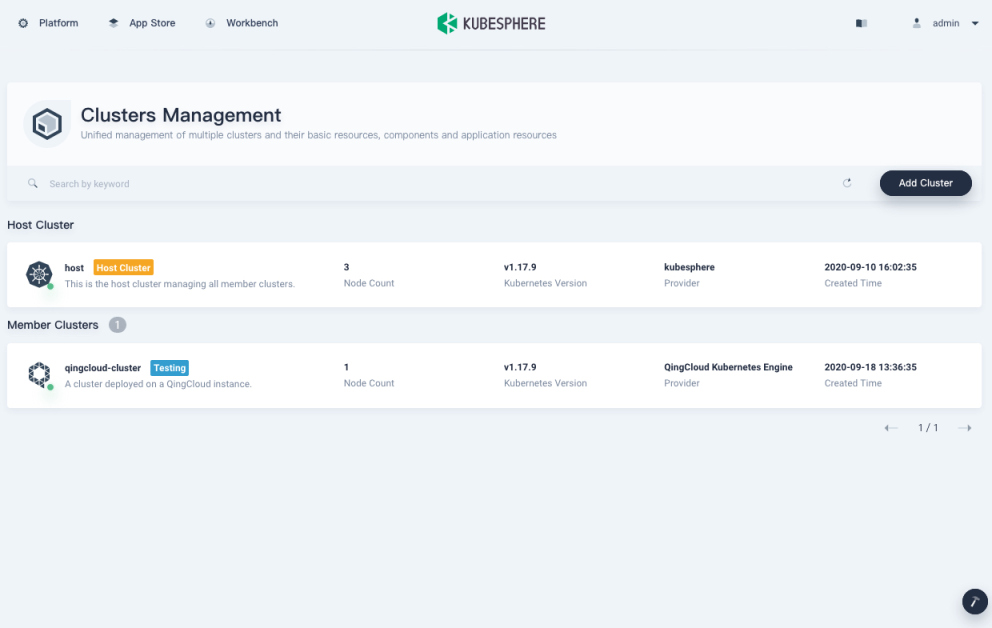
Click Platform in the top left corner and select Clusters Management.

-
If you have enabled the multi-cluster feature with member clusters imported, you can select a specific cluster to view its nodes. If you have not enabled the feature, refer to the next step directly.
-
Choose Cluster Nodes under Nodes, where you can see detailed information of node status.
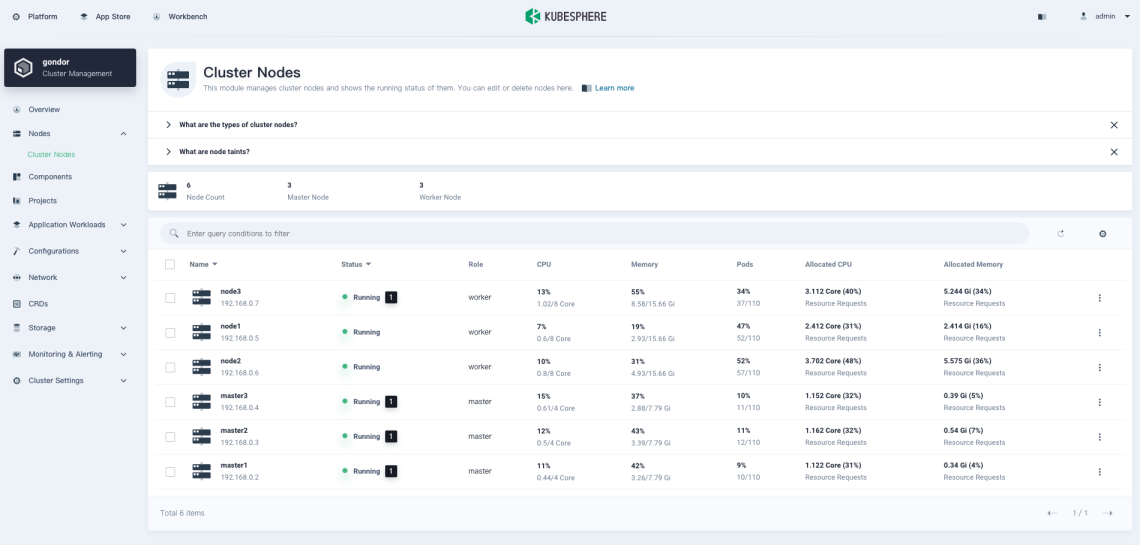
- Name: The node name and subnet IP address.
- Status: The current status of a node, indicating whether a node is available or not.
- Role: The role of a node, indicating whether a node is a worker or master.
- CPU: The real-time CPU usage of a node.
- Memory: The real-time memory usage of a node.
- Pods: The real-time usage of Pods on a node.
- Allocated CPU: This metric is calculated based on the total CPU requests of Pods on a node. It represents the amount of CPU reserved for workloads on this node, even if workloads are using fewer CPU resources. This figure is vital to the Kubernetes scheduler (kube-scheduler), which favors nodes with lower allocated CPU resources when scheduling a Pod in most cases. For more details, refer to Managing Resources for Containers.
- Allocated Memory: This metric is calculated based on the total memory requests of Pods on a node. It represents the amount of memory reserved for workloads on this node, even if workloads are using fewer memory resources.
Note
CPU and Allocated CPU are different most times, so are Memory and Allocated Memory, which is normal. As a cluster administrator, you need to focus on both metrics instead of just one. It’s always a good practice to set resource requests and limits for each node to match their real usage. Over-allocating resources can lead to low cluster utilization, while under-allocating may result in high pressure on a cluster, leaving the cluster unhealthy.
Node Management
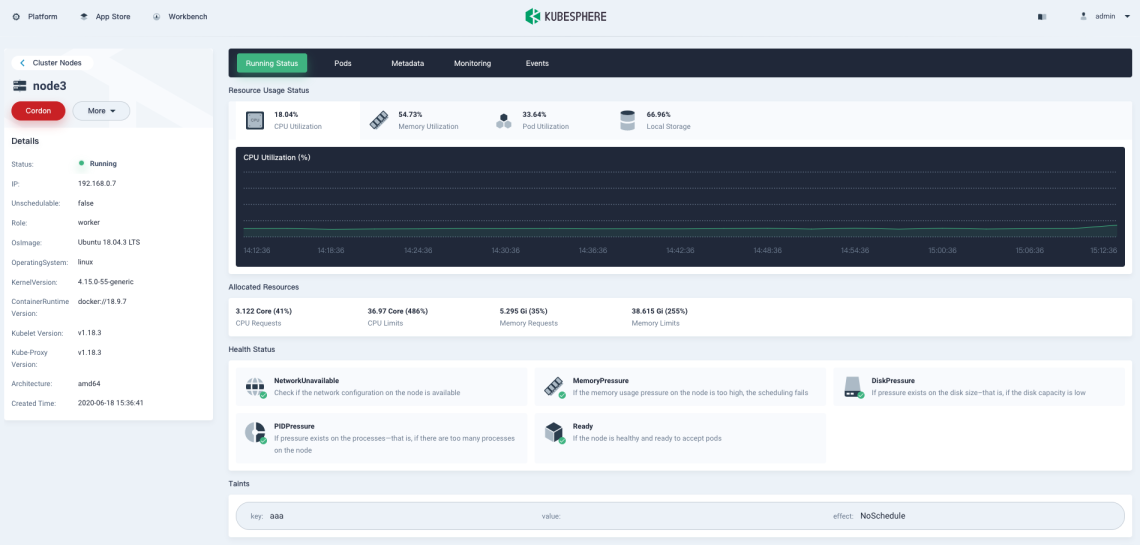
Click a node from the list and you can go to its detail page.
-
Cordon/Uncordon: Marking a node as unschedulable is very useful during a node reboot or other maintenance. The Kubernetes scheduler will not schedule new Pods to this node if it’s been marked unschedulable. Besides, this does not affect existing workloads already on the node. In KubeSphere, you mark a node as unschedulable by clicking Cordon on the node detail page. The node will be schedulable if you click the button (Uncordon) again.
-
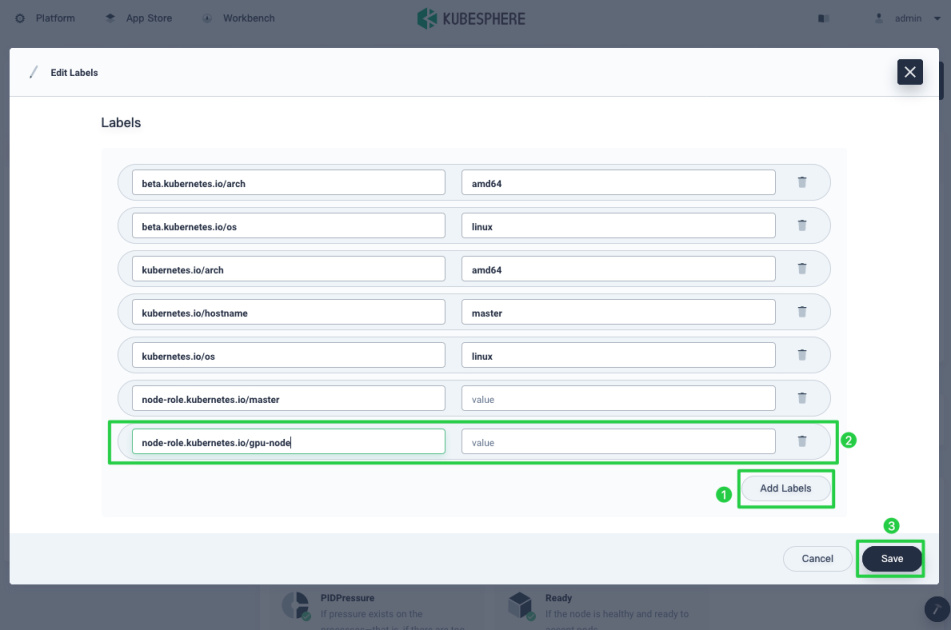
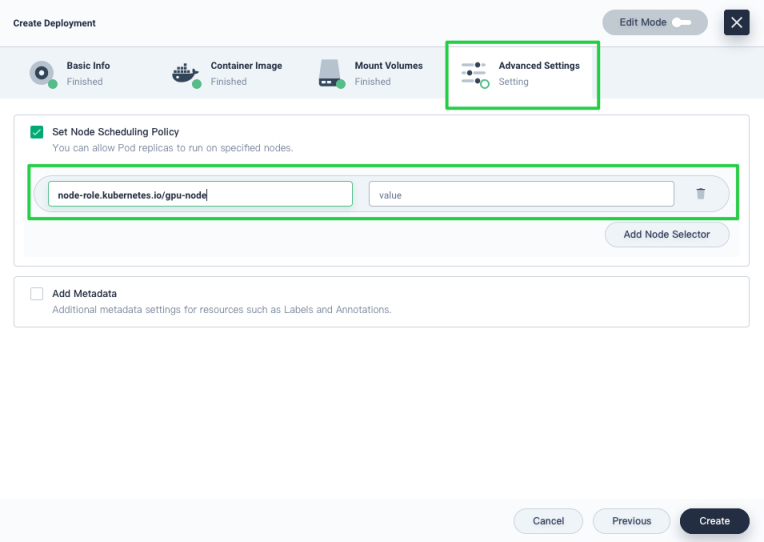
Labels: Node labels can be very useful when you want to assign Pods to specific nodes. Label a node first (for example, label GPU nodes with
node-role.kubernetes.io/gpu-node), and then add the label in Advanced Settings when you create a workload so that you can allow Pods to run on GPU nodes explicitly. To add node labels, click More and select Edit Labels.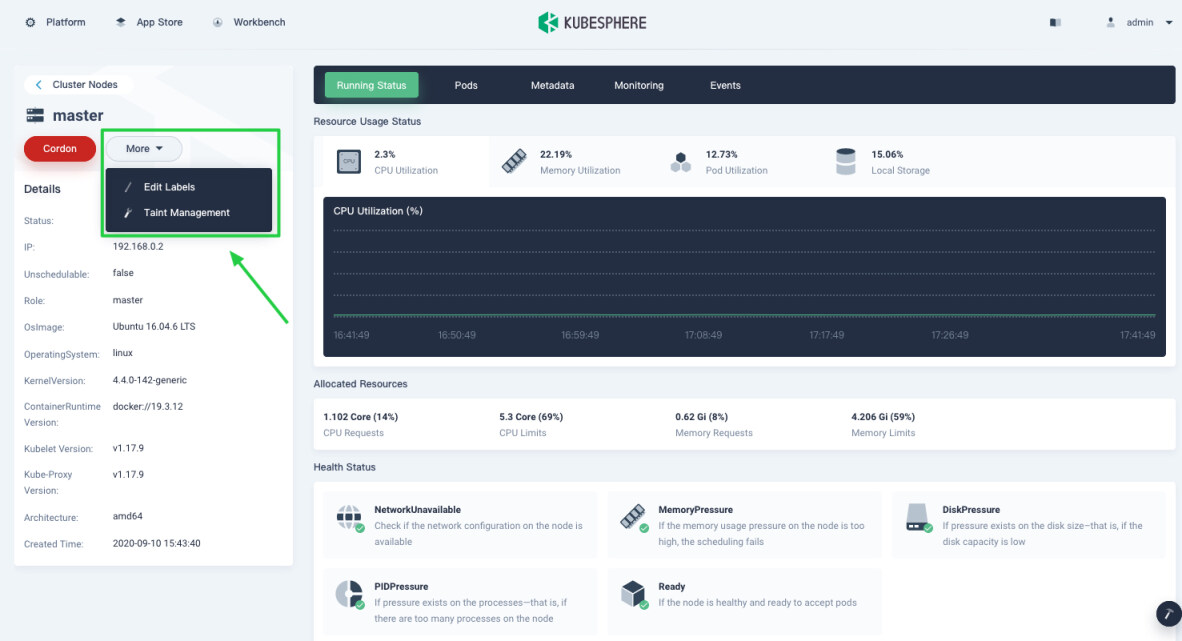
-
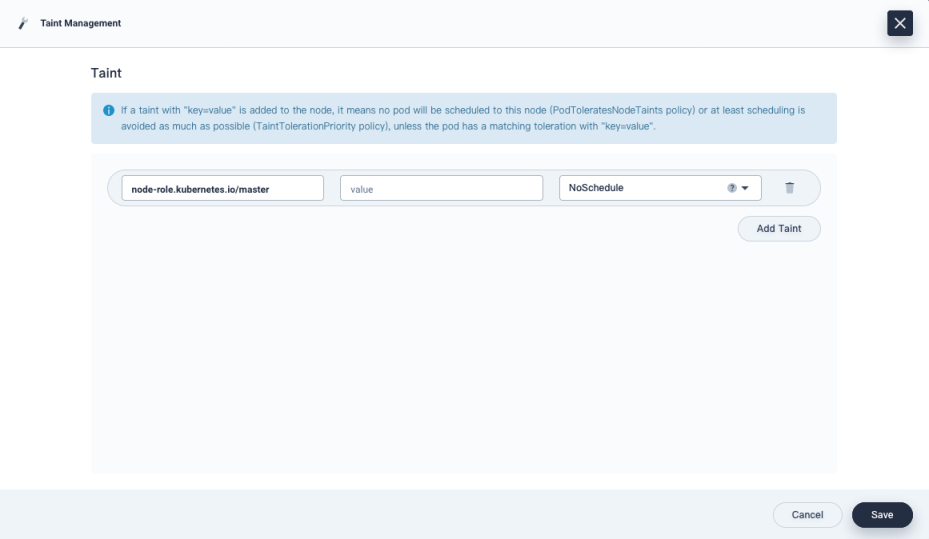
Taints: Taints allow a node to repel a set of pods. You add or remove node taints on the node detail page. To add or delete taints, click More and select Taint Management from the drop-down menu.
Note
Be careful when you add taints as they may cause unexpected behavior, leading to services unavailable. For more information, see Taints and Tolerations.
Add and Remove Nodes
Currently, you cannot add or remove nodes directly from the KubeSphere console, but you can do it by using KubeKey. For more information, see Add New Nodes and Remove Nodes.
 Previous
Previous

What’s on this Page