






You are viewing documentation for KubeSphere version:v3.0.0
KubeSphere v3.0.0 documentation is no longer actively maintained. The version you are currently viewing is a static snapshot. For up-to-date documentation, see the latest version.






Account Login Failure
KubeSphere automatically creates a default account (admin/P@88w0rd) when it is installed. After ks-controller-manager synchronizes statuses of accounts to OpenLDAP and Jenkins, accounts and passwords will be encrypted. An account cannot be used for login until the status reaches Active.
Here are some of the frequently asked questions about account login failure.
Account Not Active
You may see an image below when the login fails. To find out the reason and solve the issue, perform the following steps:
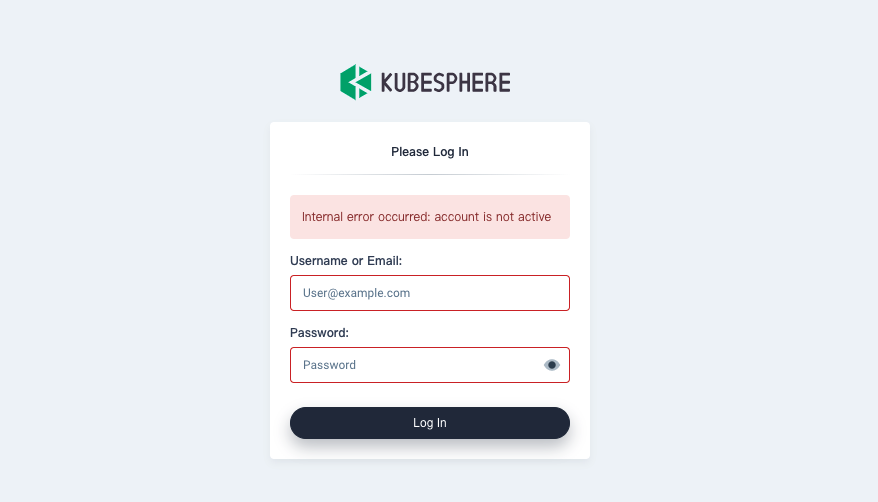
-
Execute the following command to check the status of your account.
$ kubectl get users NAME EMAIL STATUS admin admin@kubesphere.io Active -
Verify that
ks-controller-manageris running and check if exceptions are contained in logs:kubectl -n kubesphere-system logs -l app=ks-controller-manager
Here are some possible reasons for this issue.
Admission webhooks malfunction in Kubernetes 1.19
Kubernetes 1.19 uses Golang 1.15 in coding, requiring the certificate for admission webhooks to be updated. This causes the failure of ks-controller admission webhook.
Related error logs:
Internal error occurred: failed calling webhook "validating-user.kubesphere.io": Post "https://ks-controller-manager.kubesphere-system.svc:443/validate-email-iam-kubesphere-io-v1alpha2-user?timeout=30s": x509: certificate relies on legacy Common Name field, use SANs or temporarily enable Common Name matching with GODEBUG=x509ignoreCN=0
For more information about the issue and solution, see this GitHub issue.
ks-controller-manager malfunctions
ks-controller-manager relies on two stateful Services: OpenLDAP and Jenkins. When OpenLDAP or Jenkins goes down, ks-controller-manager will be in the status of reconcile.
Execute the following commands to verify that OpenLDAP and Jenkins are running normally.
kubectl -n kubesphere-devops-system get po | grep -v Running kubectl -n kubesphere-system get po | grep -v Running kubectl -n kubesphere-system logs -l app=openldap
Related error logs:
failed to connect to ldap service, please check ldap status, error: factory is not able to fill the pool: LDAP Result Code 200 \"Network Error\": dial tcp: lookup openldap.kubesphere-system.svc on 169.254.25.10:53: no such host
Internal error occurred: failed calling webhook “validating-user.kubesphere.io”: Post https://ks-controller-manager.kubesphere-system.svc:443/validate-email-iam-kubesphere-io-v1alpha2-user?timeout=4s: context deadline exceeded
Solution
You need to restore OpenLDAP and Jenkins with good network connection. Restarting ks-controller-manager will trigger reconcile immediately. When the connection to OpenLDAP or Jenkins fails, the retry interval will increase.
kubectl -n kubesphere-system rollout restart deploy ks-controller-manager
Wrong code branch used
If you used the incorrect version of ks-installer, the versions of different components would not match after the installation. Execute the following commands to check version consistency. Note that the correct image tag is v3.0.0.
kubectl -n kubesphere-system get deploy ks-installer -o jsonpath='{.spec.template.spec.containers[0].image}' kubectl -n kubesphere-system get deploy ks-apiserver -o jsonpath='{.spec.template.spec.containers[0].image}' kubectl -n kubesphere-system get deploy ks-controller-manager -o jsonpath='{.spec.template.spec.containers[0].image}'
Wrong Username or Password
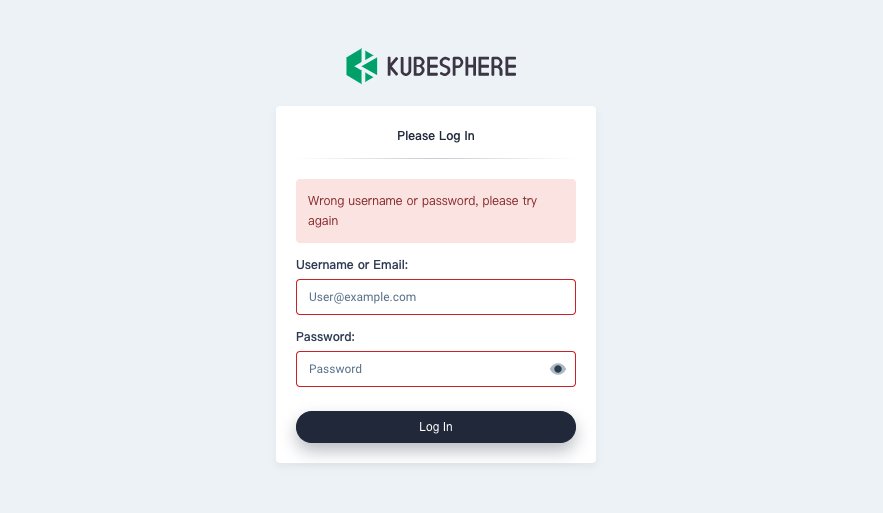
ks-console and ks-apiserver use Redis to share data across multiple copies. When Redis fails, the copies of ks-console will not be able to share the salt required for password encryption and transmission.
Run the following command to verify that the account and the password are correct.
curl -u <USERNAME>:<PASSWORD> "http://`kubectl -n kubesphere-system get svc ks-apiserver -o jsonpath='{.spec.clusterIP}'`/api/v1/nodes"
Redis failure
Use the following commands to verify that Redis is running normally.
kubectl -n kubesphere-system logs -l app=ks-console kubectl -n kubesphere-system get po | grep -v Running # High Availability kubectl -n kubesphere-system exec -it redis-ha-server-0 redis-cli info replication kubectl -n kubesphere-system exec -it redis-ha-server-0 -- sh -c 'for i in `seq 0 2`; do nc -vz redis-ha-server-$i.redis-ha.kubesphere-system.svc 6379; done' kubectl -n kubesphere-system logs -l app=redis-ha-haproxy kubectl -n kubesphere-system logs -l app=redis-ha # Single Replica kubectl -n kubesphere-system logs -l app=redis
Related error logs:
1344:C 17 Sep 2020 17:13:18.099 # Failed opening the RDB file dump.rdb (in server root dir /data) for saving: Stale file handle
1:M 17 Sep 2020 17:13:18.198 # Background saving error
1:M 17 Sep 2020 17:13:24.014 * 1 changes in 3600 seconds. Saving...
1:M 17 Sep 2020 17:13:24.015 * Background saving started by pid 1345
1345:C 17 Sep 2020 17:13:24.016 # Failed opening the RDB file dump.rdb (in server root dir /data) for saving: Stale file handle
1:M 17 Sep 2020 17:13:24.115 # Background saving error
E0909 07:05:22.770468 1 redis.go:51] unable to reach redis host EOF
[WARNING] 252/094143 (6) : Server check_if_redis_is_master_0/R0 is DOWN, reason: Layer7 timeout, info: " at step 5 of tcp-check (expect string '10.223.2.232')", check duration: 1000ms. 2 active and 0 backup servers left. 0 sessions active, 0 requeued, 0 remaining in queue.
[WARNING] 252/094143 (6) : Server check_if_redis_is_master_0/R1 is DOWN, reason: Layer7 timeout, info: " at step 5 of tcp-check (expect string '10.223.2.232')", check duration: 1000ms. 1 active and 0 backup servers left. 0 sessions active, 0 requeued, 0 remaining in queue.
[WARNING] 252/094143 (6) : Server check_if_redis_is_master_0/R2 is DOWN, reason: Layer7 timeout, info: " at step 5 of tcp-check (expect string '10.223.2.232')", check duration: 1000ms. 0 active and 0 backup servers left. 0 sessions active, 0 requeued, 0 remaining in queue.
[ALERT] 252/094143 (6) : backend 'check_if_redis_is_master_0' has no server available!
Solution
You need to restore Redis and make sure it is running normally with good network connection between Pods. After that, restart ks-console to synchronize the data across copies.
kubectl -n kubesphere-system rollout restart deploy ks-console
 Previous
Previous

What’s on this Page